Seeking Synthfeld


For the last week or so, I’ve been in a holding pattern. I have a baby coming any day now, but as anybody who has had a baby can tell you, they rarely arrive on schedule. That means I have time on my hands as I wait for the big day. Bereft of my usual diversions, I have been watching Seinfeld.
I took some screenwriting in graduate school, and part of a screenwriter’s job is maintaining a character’s voice. Audiences expect a character to speak and behave a certain way and maintain their particularities season after season. Seinfeld is, of course, famous for its distinct, idiosyncratic characters. Watching it, I became curious about the crossover between this dramaturgical problem and language modeling. How well would a language model be able to represent the particular idiosyncrasies of Seinfeld characters?
With that, I began work on a quick, week-long project of training a Seinfeld language model. The result was Synthfeld: a fine-tune of a Llama model on Seinfeld scripts. You can chat with Synthfeld here. Training and testing Synthfeld had some interesting results, and I thought I would share them below.
Set-Up
Prior art here is Nothing, Forever, a procedurally-generated sitcom from 2022 that used the Unity engine and Chat-GPT API calls to endlessly generate a Seinfeld-style Twitch livestream. While Nothing, Forever was an interesting project for its time, a lot of things have improved since 2022. We now have access to more open source models, cheaper chip time, and easier-to-use fine-tuning harnesses, which enabled me to run quantitative and qualitative tests to find how well the model learned a given character's voice.
Unlike, say, the corpus of Victorian literature in English, there is not enough Seinfeldia in existence to train an AI model exclusively on Seinfeld. Fortunately, every single Seinfeld script has been transcribed. So rather than train a model from scratch, I opted for a two-step process using LoRA adapters on top of a well-studied, open-source base model—specifically Llama-3.1-8B Base. The first adapter would be continued pretraining of the base model to change the base representations and make it more Seinfeldian, while the second adapter would fine-tune the model using Seinfeld scripts adapted to a chat template. Both adapters would be merged with the base model weights in two rounds.
For assessment, I planned out a battery of quantitative tests, including a perplexity test and an attribution test. The perplexity test would assess how well the model learned to predict Seinfeld text. In the attribution test, I would show the model a line, and ask it to guess the most probable character to have spoken that line. The attribution test would allow me to assess how well the model had developed internal representation of the characters' voices. Other tests included a linear probe, a test to date scripts by season/era, and a "Story Cloze" test—all discussed below.
Finally, I would assess how well the model generated a Seinfeld line with an online quiz asking users to pick the "real" Seinfeld line out of a line up. If my model "fooled" live users, that means that it would have effectively learned to ape the voice of Seinfeld characters. You can take the quiz here if you are so inclined!
My hypothesis was that the Synthfeld model would perform better than both Llama-base and Llama-instruct on the quantitative tests. I also believe that my model would perform better on the qualitative test (i.e. that it would generate more believable Seinfeld lines), but that the real, human-written lines would win handily.
Read on to see how wrong I was!
Pretraining and SFT
Assembling the dataset and commencing pretraining was fairly easy. There are 180 episodes of Seinfeld. I divided these into 157 “training” episodes, 8 “validation” episodes, and held 10 episodes out for later testing.
Before training commenced, I needed to make a decision: how would I teach the model to speak in the voice of one specific character or another, and not just collapse into a generic “All of Seinfeld” voice? In other words, how would I be able to easily swap out characters at inference? I accomplished this by adding a set of special character tokens to the tokenizer, and tagging the beginning of every line in the SFT dataset with the character token. So, the training data looked something like this:
{"role": "user", "content": "So what did you do?"}
{"role": "assistant", "content": "[GEORGE] I told her I would have to think about it."}
This way, the model learned to emit George-like lines when its response was appended with the [GEORGE] token, Jerry lines with the [JERRY] token, etc. Rather than switching out adapters or anything like that, the model would just switch out which token is appended to the “assistant” response during inference, and the learning would take care of whatever followed.
From there, I ran a parser over the scripts to take out junk like stage directions and the occasional webpage navigation copy. These 157 training episodes tokenized into about 787,000 training tokens, and pretraining and merging the first LoRA adapter took roughly an hour.
Adapting the scripts for SFT training was more challenging. Most of the scripts had no clear, machine-readable demarcation of when a scene began or ended. Ultimately, I opted for a sliding-window method that chunked the scripts into scenes of between 4 and 16 lines. Even with this done, though, many of the scenes were multi-character, and I was training the model to do two-character back-and-forth interaction with a user.
I opted for a system where a multi-character scene would be repeated in the training data multiple times, with “User” and “Assistant” passes assigned to different characters with each repetition. A Jerry/George/Elaine/Kramer scene would appear 4 times: once with Jerry’s line assigned to the assistant, once with George’s lines assigned to the assistant, and so on. These yielded 7,891 scenes, or 30,225 user turns. I set my initial number of SFT training epochs for 3, but the loss curve began to creep back up during the second epoch, so in the end I only did one epoch for SFT.
Quantitative Testing
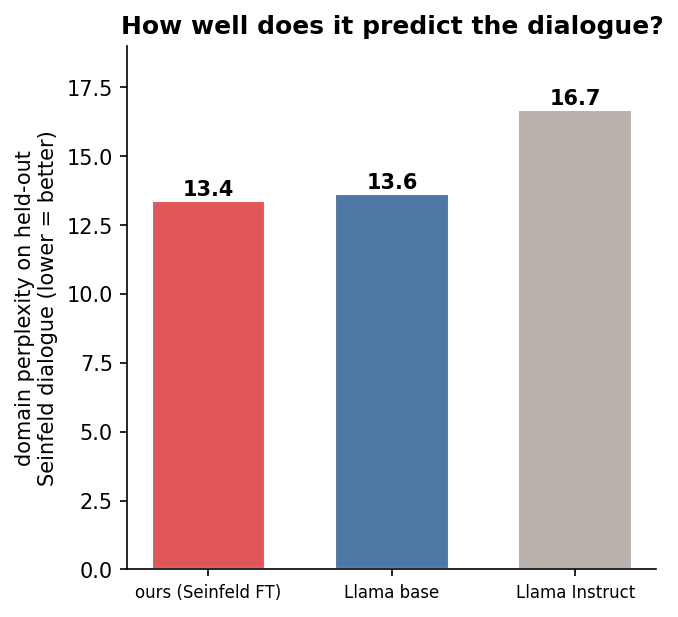
With my model trained and downloaded, I began to run tests. As I mentioned, I had 10 episodes held out from my training data, which yielded 2,220 scenes. All the tests that follow used those held-out scenes as my testing data. The perplexity result was the first surprise. Synthfeld performed about equally to Llama-base, while I had expected it to perform better. That said, given the fact that the scripts have been fan-transcribed and are available on the internet, it's likely that Llama-base was already trained on Seinfeld scripts. Synthfeld performed slightly better than Llama-instruct, but instruct-tuning is known to slightly degrade perplexity on broad benchmarks:
The attribution test was even more surprising. It was designed to measure the model’s ability to assess P( line | [CHARACTER] ), or the probability that a line fits a given character’s voice. I had trained the model on five characters (the main cast + Newman), which gave a baseline-random guess of .2, and a baseline-majority of .365—representing the proportion of Jerry’s lines. This meant that if the model were to simply guess Jerry every time, it would get it right 36.5% of the time.
I ran two attribution tests: the first with the scene's full context (so, all of the preceding lines), and the second with zero context (i.e. the line alone). In both tests, I stripped out all proper names, so that I knew the models wouldn't be relying on names said in-dialogue to determine who was speaking. Interestingly, the Syntheld model was able to attribute voice properly 43.4% of the time with context, but Llama-base and Llama-instruct both outperformed Synthfeld by a large margin. Without context, the models were roughly equal, with Synthfeld just barely edging out the Llamas.
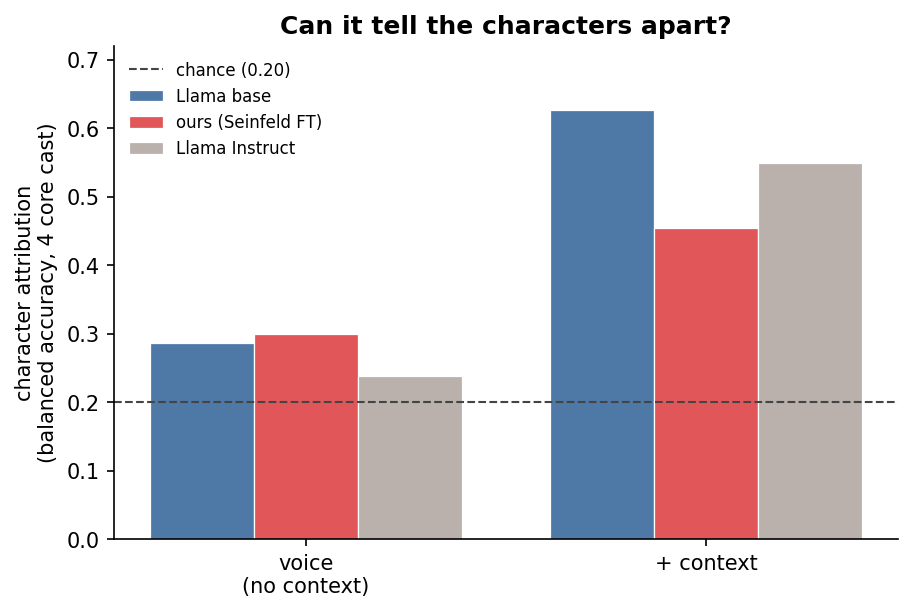
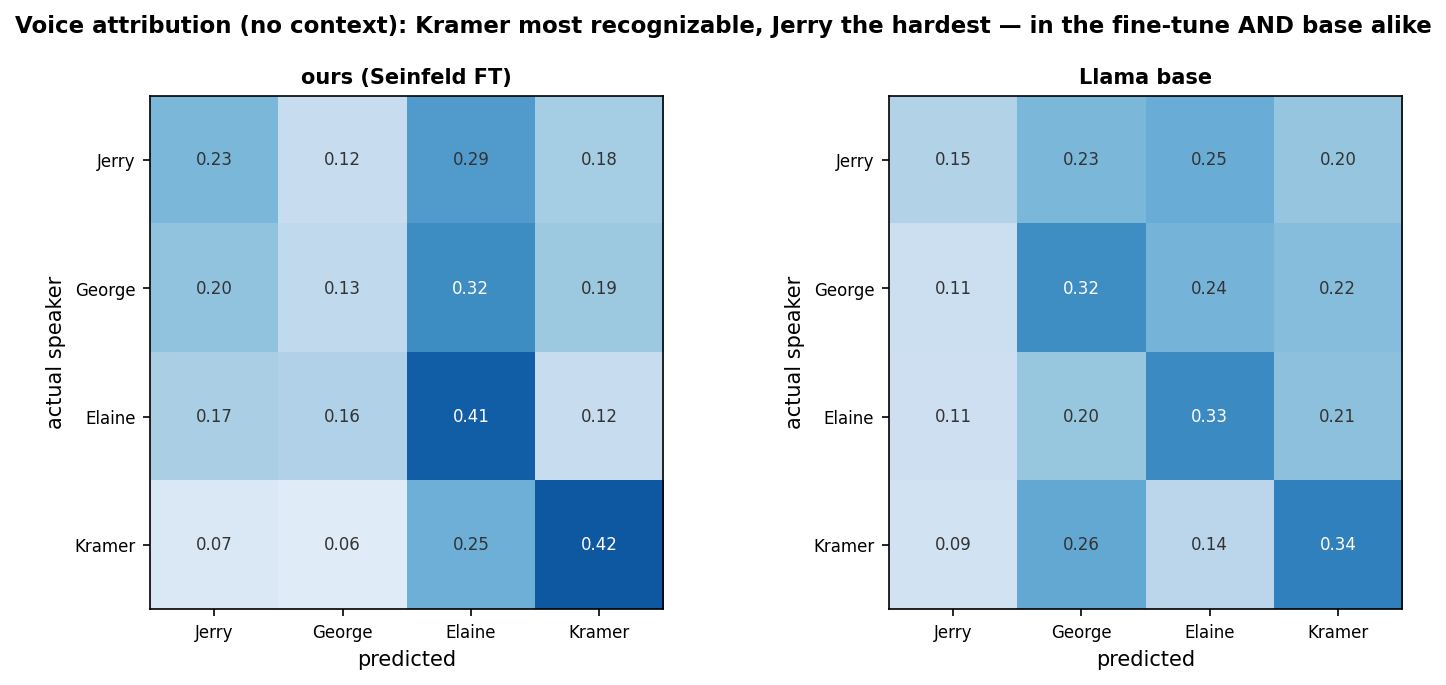
What does this mean? It means that, on the attribution test, the models were looking at the context of the conversations and inferring the next result, not learning the character's voices in isolation—for the most part. Maybe the most interesting number was the per-character recall on the name-stripped voice attribution. Kramer and Elaine's voices were highly distinctive, while George and Jerry's were less so. In other words, my model was able to pick up on Kramer and Elaine, less so on George and Jerry. Synthfeld was only able to predict George's voice correctly 13% of the time!
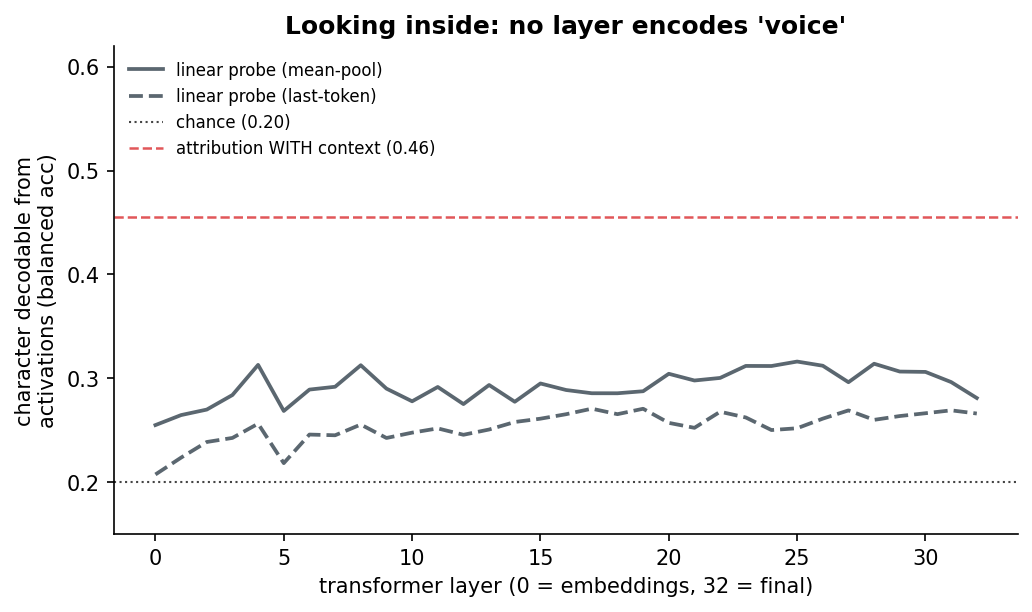
I also ran a season/era test to see if the model could guess the season from a held-out script, but the result was null. The model couldn’t guess the season given a specific script. I also attempted to run a linear probe, to see where in the model the character voice attribution was living, but it was basically flat.
The adapted Story Cloze test revealed another interesting wrinkle: my specialist model was outperformed by both Llama-base and Llama-instruct! Story Cloze was originally created to assess story understanding in models, and my adapted test involved showing the model the preceding lines of a scene, and asking it to pick the real next line out of a lineup. While the attribution test measured who was speaking, the Story Cloze test measured which line was to come next. Both Llama-base and Llama-instruct outperformed my model:
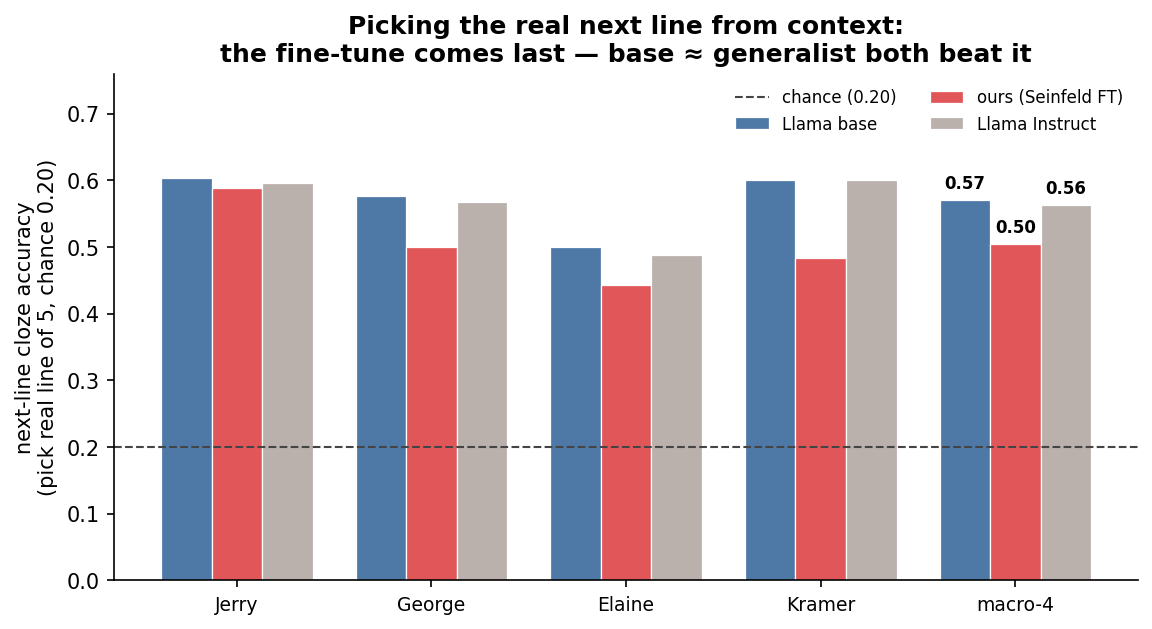
So, Synthfeld was outperformed by Llama-base and Llama-instruct on basically all of my quantitative tests. It barely edged them out on the perplexity and (no-context) attribution, but not by enough to be statistically significant. The lesson here: never bet against Mark Zuckerberg. Or maybe more seriously: specialized domain training alone does not confer the analytic abilities of generalized instruction tuning. The base model likely already knew Seinfeld, and my DAPT and SFT only conferred form and style. This reinforces the finding from the well-known LIMA paper, which is that almost all knowledge in a large language model is learned during pretraining.
Qualitative Tests
Ultimately, I wasn't complete surprised that the Llama models performed better than Synthfeld on the quantitative tests. Synthfeld was trained as a generation model, so a true evaluation of its capacities would involve verifying whether or not it could generate believable Seinfeld lines under controlled circumstances. I designed a quiz with two parts. The first would be a continuation test: the model would be shown the lead-up lines, and asked to write a given character's line that follows. The second part would be an infill test. Given the lines before and after, would the model be able to generate a believable line in-between? I would ask users to pick out the real line among three options: the human-written line, the line written by Llama-instruct, and the line written by Synthfeld.
Unfortunately, Synthfeld's lines generated for the infill portion of the test were unusable, but Llama-instruct, with its superior reasoning capabilities, was able to generate lines that I thought were passable enough. I kept round 2, though, as a general test of how well Llama-instruct was able to match Seinfeld pitch and tone, since it performed well at telling the characters apart in the attribution test.
In the continuation test, Synthfeld was slightly more successful than Llama-instruct, but not enough to be significantly significant. Synthfeld and Llama-instruct were about equally proficient at producing lines that real users mistook for authentic Seinfeld lines. What was perhaps more interesting was the fact that users picked AI-generated lines 48% of the time, and human-generated lines 52% of the time. I was expecting the human-generated lines to significantly outperform the AI-generated lines, but when it came to human vs AI overall, it was basically a coin flip for the continuation round. When it came to the more challenging task of fitting a line within the dramatic context of a scene, the human writers won handily. The real line was chosen 79% of the time, and the AI line only 21% of the time.
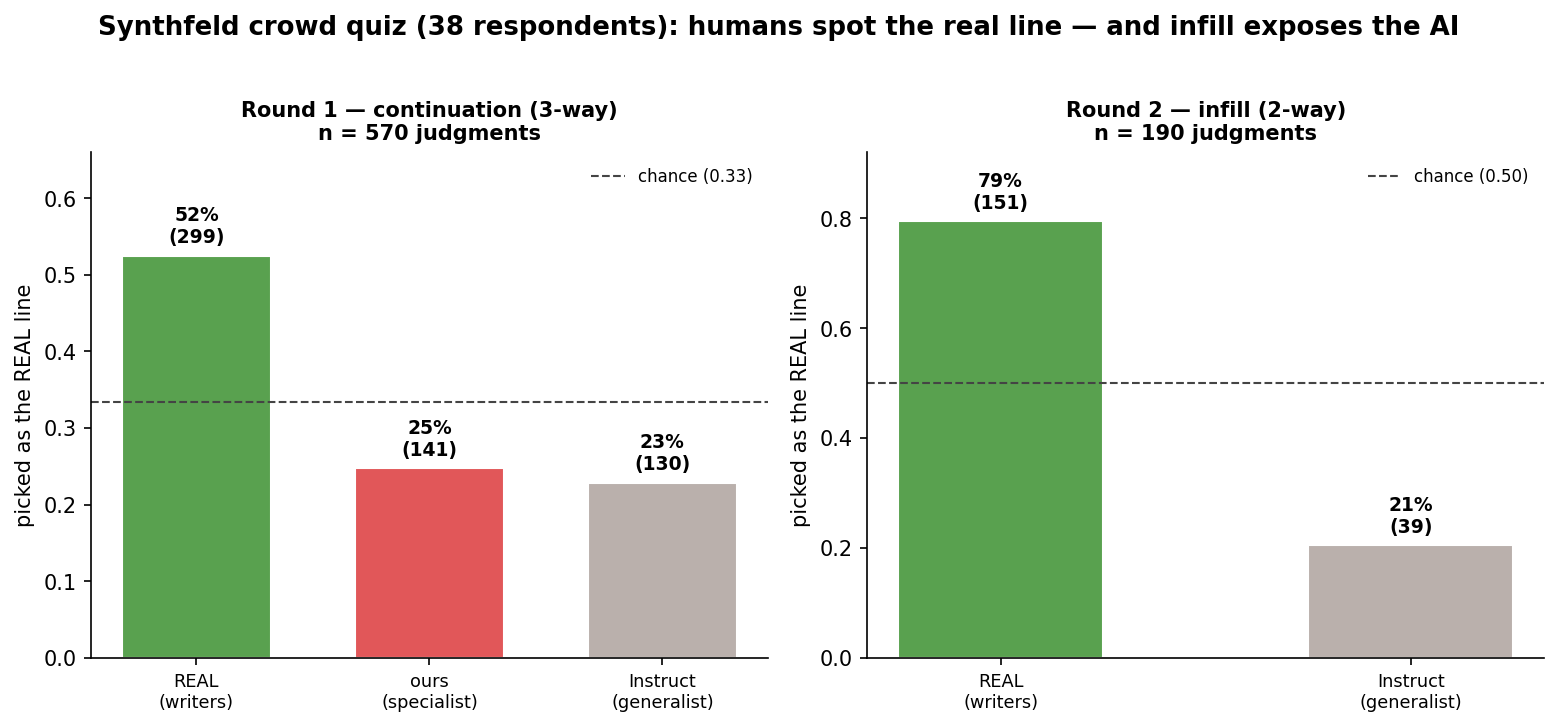
One caveat here: this test only had 38 respondents, mostly my Twitter and Bluesky followers, so it is likely that there was some self-selection of Seinfeld-savvy audience.
Conclusion
And so, my various hypotheses were proven (partially) incorrect. Synthfeld performed worse that Llama-base and Llama-instruct on many of the quantitative tests. When it performed better it wasn't by enough to be statically significant. As I mentioned above, the quantitative tests confirmed the LIMA result: fine-tuning brought behavior, not domain knowledge or specialization. Finally, Synthfeld performed roughly the same (but not much better) that Llama-instruct on the qualitative continuation test, and Llama-instruct performed poorly on the infill test.
To bring it back to my original question: how well did a language model learn to represent the idiosyncrasies of Seinfeldcharacters? The answer is, not much better than a generalized instruction-tuned model! A rather disappointing result, but fun to play around with while we wait on baby to arrive. Try it out here!


